Appearance
DeepSeek-R1
基础概念
- DeepSeek-V3: 普通对话模型
- DeepSeek-V3-Base: 只进行了预训练,没有进行指令微调的模型
- DeepSeek-R1: 推理型模型,在回答问题之前,先会进行thinking,然后给出推理过程,最后给出答案。
- DeepSeek-R1-Zero: 推理型模型,和DeepSeek-R1架构相同,但是没有进行有监督微调,直接从DeepSeek-V3 base模型进行强化学习训练得到。
- SFT: Supervised Fine-Tuning,有监督微调,是一种在预训练模型基础上,使用有标签数据进行进一步训练的技术。它通常用于将通用预训练模型适应特定任务。通过在有标签数据上微调预训练模型,使其更好地适应特定任务,如文本分类、命名实体识别等。
- 蒸馏模型权重:模型压缩技术,旨在将复杂模型(教师模型)的知识转移到更小、更简单的模型(学生模型)中,同时保持性能。其中目前所说的1.5b,7b,8b,14b,32b,70b都是蒸馏模型权重,671b为满血模型权重。
- DeepSeek官网:https://deepseek.com/
- DeepSeek R1 GitHub项目地址:https://github.com/deepseek-ai/DeepSeek-R1
- DeepSeek R1 Hugging Face项目地址:https://huggingface.co/deepseek-ai/DeepSeek-R1
- DeepSeek R1魔搭社区地址:https://modelscope.cn/models/deepseek-ai/DeepSeek-R1/
R1简介
2025年1月20日,DeepSeek发布R1大模型,并同步开源模型权重。DeepSeek-R1 在后训练阶段大规模使用了强化学习技术,在仅有极少标注数据的情况下,极大提升了模型推理能力。在数学、代码、自然语言推理等任务上,性能比肩 OpenAI o1 正式版。  相关论文链接: https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf
相关论文链接: https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf
本次开源 DeepSeek-R1-Zero 和 DeepSeek-R1 两个 660B 模型的同时,通过 DeepSeek-R1 的输出,蒸馏了 6 个小模型开源给社区,其中 32B 和 70B 模型在多项能力上实现了对标 OpenAI o1-mini 的效果 
R1开源情况介绍
DeepSeek R1采用了和DeepSeekv3完全相同的架构,只是训练过程和训练数据不同。具体来说,DeepSeek R1是在DeepSeekV3 base模型基础上,先进行了有监督学习微调,然后再进行强 化学习训练最终获得的模型,而同时开源的DeepSeek R1 Zero则是少了有监督微调步骤,直接从 DeepSeekV3 base上经过强化学习训练得到。 因此,我们看DeepSeek R1项目,其实并没有看到模型权重和推理脚本、以及本地部署方法等关键信息。因为这些信息都已经包含在DeepSeekV3模型项目中了,具体项目地址见:https://github.com/deepseek-ai/DeepSeek-V3 DeepSeekV3项目结构如下,其中红色框选部分为模型推理和架构的相关代码: 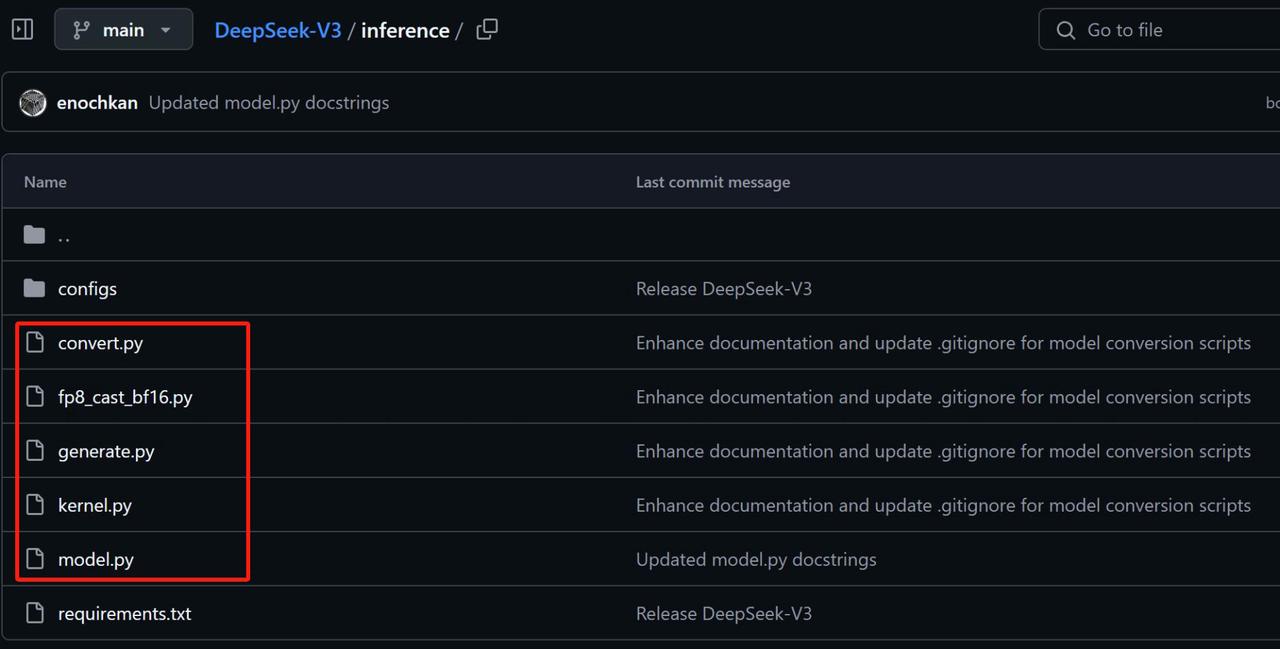
- convert.py:用于进行格式转化,将一个已经训练好的模型检查点(checkpoint)文件从一个格式(比如safetensors)转换并保存成一个适合特定模型并行度(model parallelism)和专家数(n_experts)的格式
- fp8_cast_bf16.py:代码的功能是将存储在 FP8 格式中的模型权重转换为 BF16 格式,并保存转换 后的权重。它还更新了模型的索引文件,去除了 scale_inv 的引用。
- generate.py:代码是一个用于生成文本的示例程序,支持交互式和批量文本生成。它使用一个 Transformer 模型并进行分布式训练。
- kernel.py:代码主要涉及量化和矩阵乘法操作,使用了 Triton 库进行加速,特别是针对 FP8 精度 (浮点8位)进行了优化。 Triton 是一个专为 GPU 上的高效自定义操作而设计的编程框架,支持 Python 和 PyTorch,可以通过简洁的代码来实现高效的 GPU 核心。
- model.py:定义了DeekSeekv3和R1的模型架构。